什么是大语言模型
很多人把ChatGPT = 大语言模型(大模型):
但是,大模型应用(ChatGPT)与大模型,还有大语言模型是有区别的。
只要是用文字表达的事,它都能解决?
之前也有聊天机器人,为什么它就火了?感觉它就要颠覆世界了?
...
概念
“大”、“语言”、“模型”,从逐字的角度来分析,可以帮助我们从基础概念深入理解大语言模型(LLM)。这个分析方式既能帮助初学者了解其基本含义,又能揭示这些组件之间的关系。
- “大”(Large):
“大”指的是模型的规模,包括两个方面:
参数的规模:大语言模型拥有数十亿到数万亿个参数。模型的参数越大,通常能学习到更丰富的语言模式和世界知识,从而处理更加复杂的任务。
数据的规模:大语言模型通常会在大规模的文本数据上进行训练,覆盖广泛的语言领域和多样的任务。这使得大语言模型具备更强的泛化能力(后面说明),能够应对多种应用场景。
- “语言”(Language):
这里的“语言”不仅仅指自然语言(如英语、中文),也涉及到如何理解和生成语言中的语法、语义以及上下文信息。
语言模型通过对大量文本的训练,学习如何理解句子中的词汇之间的关系,并生成符合语法和逻辑的文本。
- “模型”(Model):
大语言模型基于神经网络(尤其是Transformer架构),可以通过对输入的文本进行处理,生成语法、语义合理的输出。
ChatGPT,其中Chat是聊天的意思,而GPT是Generative Pre-Trained Transformers,直译过来就是“生成预训练变换器”。
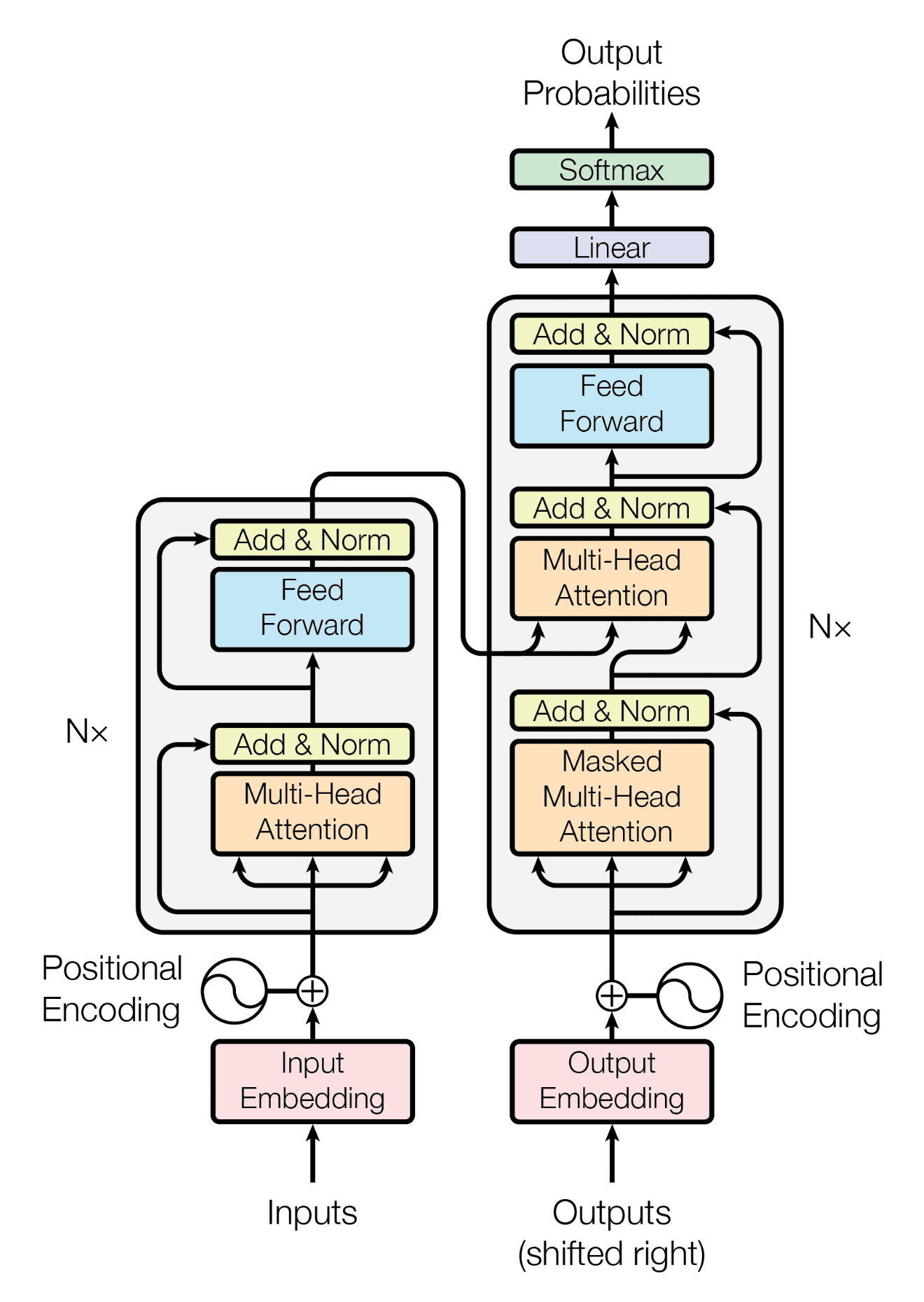
其核心任务是通过从大量数据中提取规律和知识,生成新的、相关的文本。
“大语言模型”可以被看作是一个超大规模的、处理和生成自然语言的人工智能模型,它能够理解上下文、识别语义并进行合理的文本生成。
参数
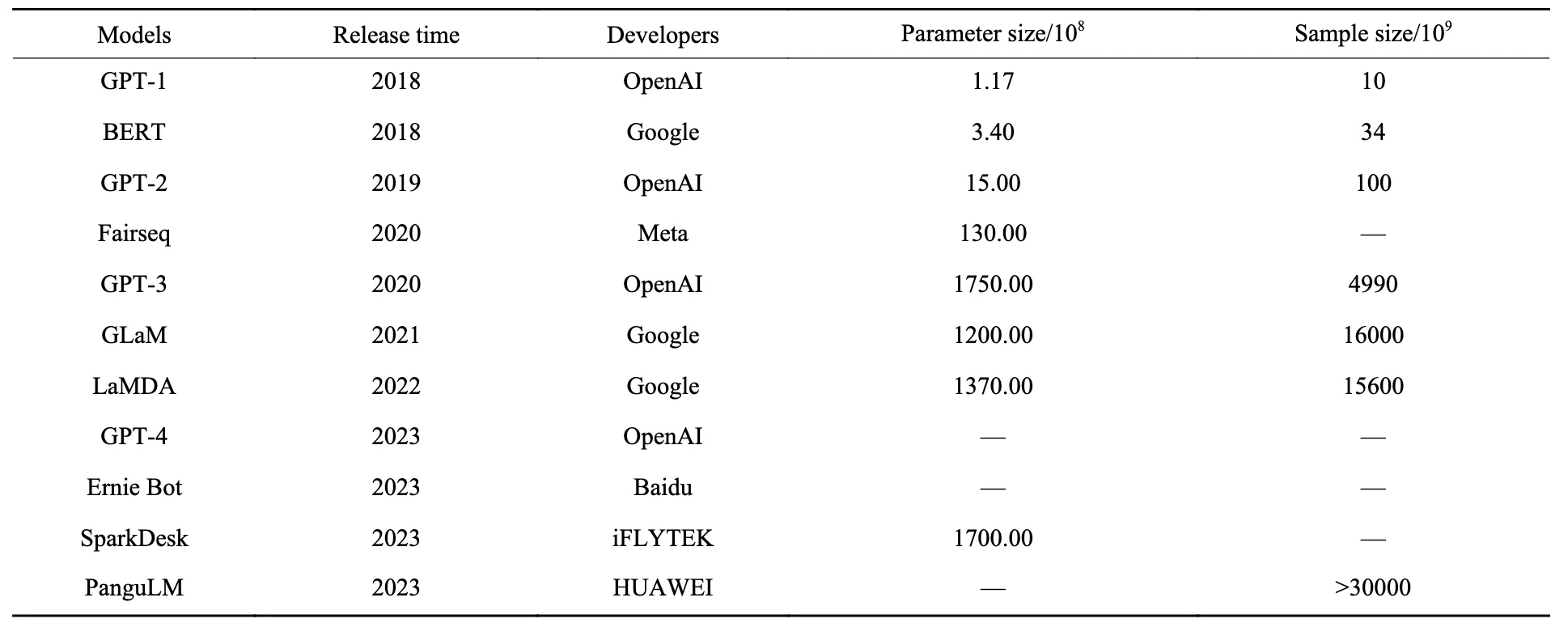
截止到2023年,上图中反映出来的是典型大模型及它们的参数量、训练数据量。
我们以GPT1为例,来说明一下大模型的参数:
在GPT(Generative Pre-trained Transformer)系列模型中,特别是GPT-1(即最初的版本)
GPT-1的架构
GPT-1的架构基于Transformer的解码器(Decoder),与传统的Encoder-Decoder架构不同,它只使用了解码器部分。它的参数量主要取决于以下几个部分:
词嵌入(Word Embedding):用来将每个输入词(或子词)转换为固定长度的向量
多头自注意力(Multi-Head Attention):每个解码器层中的核心部分,含有多个注意力头
前馈网络(Feed-Forward Network):每个解码器层中紧随自注意力模块的全连接网络
输出层(Output Layer):将最后的隐藏状态映射到词汇表中的每个词的概率分布
GPT-1的参数计算
GPT-1模型包含多个解码器层,每个解码器层包括以下几个主要部分:
词嵌入层(Word Embedding)
自注意力层(Self-Attention)
前馈神经网络(Feed-Forward Neural Network)
输出层(Output Layer)
随着模型规模的增加,GPT-2、GPT-3等模型的参数计算也遵循类似的规则,但参数量随着模型的深度(层数)、嵌入维度、头数等的增加而增长。例如:
GPT-2:具有更高的嵌入维度(例如1,024维)、更多的层(例如48层)以及更多的注意力头(例如16头)。这些因素都会导致参数量的增加。
GPT-3:嵌入维度达到12,288,层数为96层,头数为96,这使得其参数量达到了1750亿。
GPT系列模型的总参数量与以下几个因素直接相关:
层数
词嵌入的维度
每层的头数
词汇表大小
前馈网络的维度
总的来说,GPT系列模型的参数量随着这些配置的增大而呈指数级增长。
数据
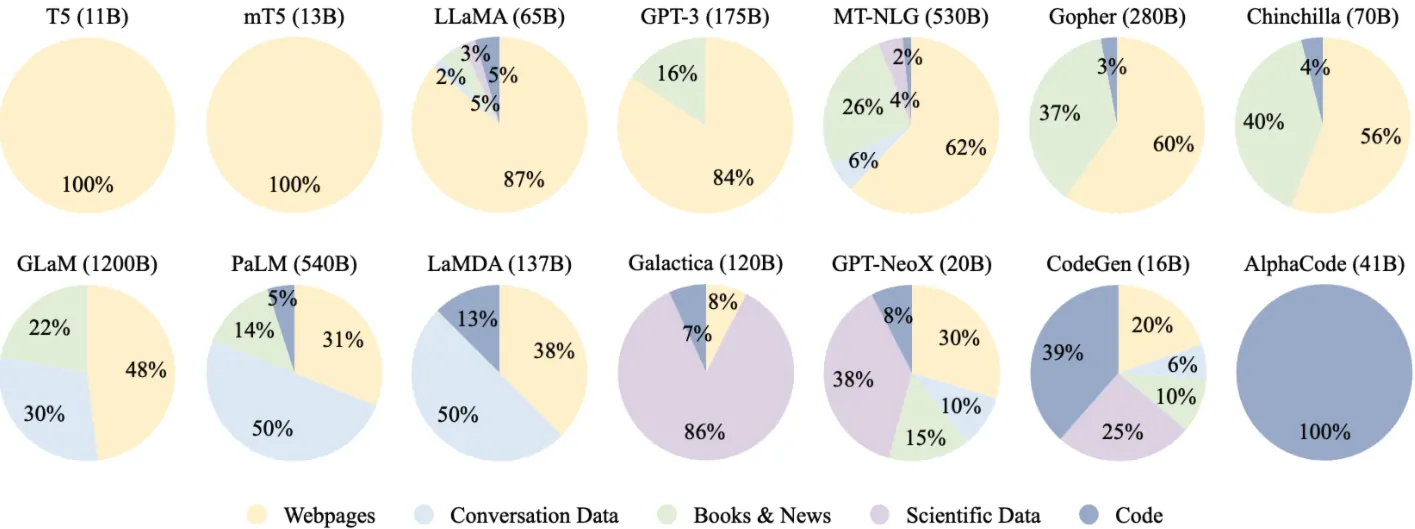
通用文本数据:绝大多数的LLM 采用了通用的预训练数据,比如网页、书籍和对话文本等,这些数据源提供了丰富的文本资源,并且涉及了多种主题。
网页数据(黄色区域)
对话数据(蓝色区域)
书籍与新闻数据(绿色区域)
科学数据(紫色区域)
代码数据(蓝色小圆圈区域)
模型的训练数据越多样化,越能帮助模型理解不同领域的知识和语言规律。例如,包含网页数据和对话数据的模型能够生成自然且流畅的对话内容,而涵盖科学数据的模型能够理解和生成专业领域的术语和技术内容。
- 丰富的语料库使模型能够学习更多语言结构和语义
模型的能力不仅取决于其规模,还取决于训练数据的质量和多样性。从图中来看,如 T5 和 mT5 这类模型几乎完全基于网页数据(100%),而 GLaM(1200B参数)则有更为广泛的训练数据,包括网页、书籍和科学数据。这些不同的文本来源帮助模型学会理解不同的语言结构、语境、情感、专业术语等,从而提升了模型生成文本的能力。
- 特定领域数据提升专业任务的表现
特定领域的数据,比如代码数据(如 AlphaCode 和 CodeGen),能够显著提高模型在特定任务上的表现。例如,AlphaCode 通过专注于代码数据,能够生成和理解代码,帮助程序员提高工作效率。这表明,针对特定任务的专用数据能够让模型在这些任务上表现得更好。
- 多任务学习和迁移能力
具有多种数据来源的模型,如 PaLM 和 LaMDA,通常具备较强的多任务学习能力。这些模型不仅能生成文本,还能进行文本分类、翻译、问答等任务。通过从多个领域的数据中学习,模型能够在一个领域的知识上“迁移”并应用到其他领域,从而表现得更加灵活和高效。
模型(机器学习)

我们广义上理解的模型,更像一个缩小版的玩具,一个对应实物的示意,作用是高仿真实的物体,传达对应的信息。
“模型”指的是使用机器学习算法,通过大量数据训练而来的数学表示。
大语言模型像是人类大脑的缩小版或“高仿真玩具模型”。它通过大量的训练数据(比如文本、对话等)来“学习”如何生成合理的输出。虽然它通过大量的计算和参数来捕捉语言规律和语义,但它并没有真正理解语言,只是在基于统计模式进行推测和生成。因此,它是一个高度精简且没有意识的仿真模型。
模型决定了机器如何学习,如何训练,如何推理(吐词)输出。
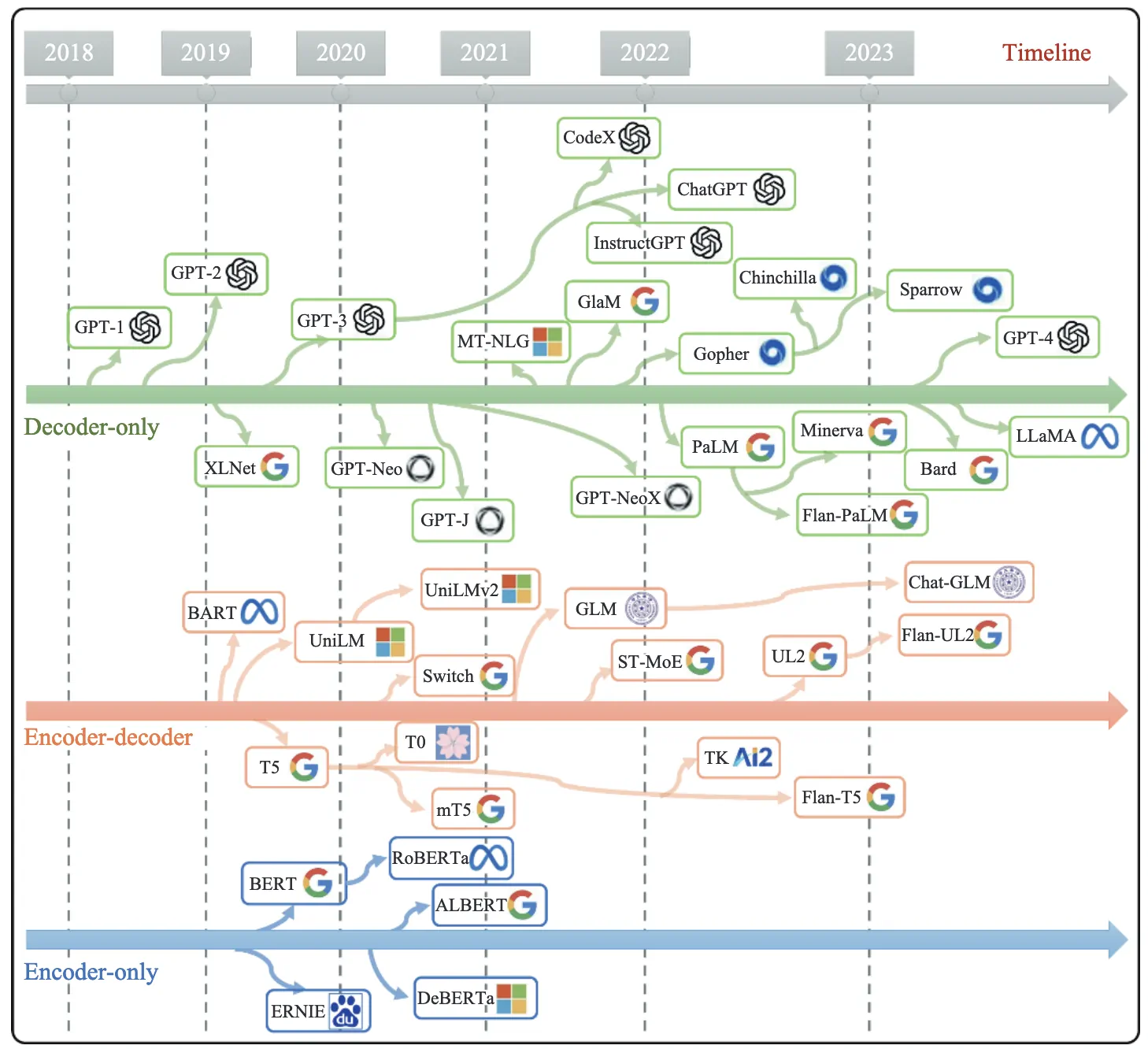
架构演进与模型对应的关系:
资源推荐
聚合API平台
一站式购买多种AI服务API,供用户选择和购买。
国外推荐:
OpenRouter:提供了大语言模型API的聚合,用户可以通过该平台购买和管理多个大语言模型的API,简化了接入多个API的复杂度。
最全面,使用量最大,而且付费也比较友好的平台,价格基本上与官方一致。
国内推荐:
AIHubMix:是一个提供API聚合的平台,用户可以通过它购买和接入各种AI模型,涵盖自然语言处理、计算机视觉等多种应用场景。
可以支付宝进行付款,部分热门模型可以会加价10%,大部分模型是平价,而且是低于官方的价格
Siliconflow:主要是国内的模型应用,下面是一些旗下的产品
- SiliconCloud:一站式大模型云服务平台,提供文本、图像、语音、视频等多模态生成服务,集成多种主流开源大模型,并内置推理加速引擎。
- SiliconLLM:高效的大语言模型推理引擎,支持国内外主流芯片部署,在超长上下文、低延迟等复杂场景中表现出色,推理速度提升最高可达10倍。
- OneDiff:高性能的文生图/视频加速库,支持Stable Diffusion等模型,性能提升高达3倍,实现1秒内生成高质量图像。
- SiliconBrain:面向企业用户的一站式AI应用开发平台,支持模型微调与托管,基于DevOps原理,实现持续集成、交付和部署,帮助企业降低维护成本。
模型平台
多种开源和商业化模型的聚合,用户可以根据需要选择不同的模型进行应用。
Hugging Face:是目前最流行的AI模型聚合平台之一,提供多种预训练模型,涵盖NLP、计算机视觉等多个领域,并且支持开源和商用模型的访问
ModelScope:由阿里巴巴提供的一个聚合平台,支持多种模型的部署与使用,提供面向各行各业的AI模型,包括NLP、CV等多种模型
Civitai:Civitai是一个专注于AI图像绘画和艺术作品创作和分享的在线平台和社区,用户可以上传和共享他们使用自己的数据训练的自定义模型(主要基于StableDiffusion),也可以浏览、下载和评论其他用户创建的模型
AI工具
关键词搜索“AI聚合网站”,“AI工具集”,“AI导航”...